
Google Lensの画像認識技術とその未来について考えてみた!
3年ほど前にネット上で話題になった画像があります。それは海外のもので、「Puppies Or Food?」(子犬たち?それとも食べ物?)と題されたその画像を紹介する記事には、ビーグルとベーグル、シープドッグとモップ、チワワとレーズンマフィンの画像が交互に並べられていました。
誰もが画像を見るまでは「まさか」と思うようなまったく違う「動物」と「物体」が、交互に並べられると実にそっくりであることに皆驚き、そして「これは見分けがつかない」と大笑いしたのです。その画像は今でも時々思い出したようにSNSに流れてきては、その度に話題となるほどです。
人はそれでも、そこに写っているものが犬なのか、それとも食べ物や道具であるのかを正しく判断することができます。例えば、WebサイトのBot(ボット)のクロール対策として画像を選択させる認証システムがありますが、あれはその画像に何が表示されているのかを少なくとも現状ではBotでは正しく判断できないという前提があればこそ可能なシステムです。
しかしながら、テクノロジーの進化はとどまるところを知りません。コンピューターはそこに表示されているものがビーグルなのか、それともベーグルなのかを人間のように判断し始めています。もはやチワワとレーズンマフィンを間違えることも、トイプードルとフライドチキンを間違えることもなくなりつつあります。たった3年の間にどのような進化があったのでしょうか。
感性の原点からテクノロジーの特異点を俯瞰する連載コラム「Arcaic Singularity」。今回はGoogleが開発した「Google Lens」を例に機械学習の仕組みを解説しながら、コンピューターの画像認識技術の最先端を追います。

■画像認識技術への挑戦は「長い旅の始まり」
ビーグルとベーグルと正しく判断するカギは、現在Googleが「Google Lens」として提供しています。
Google Lensは、物体が「何であるのか」を判断する画像認識技術です。Android端末向けには単体のアプリとしても提供されていますが、iOS端末でも「Googleフォト」アプリの一機能として利用できます。
Google Lensアプリはその場で撮ったものが何であるのかを瞬時に判断して教えてくれる
これらの瞬間的な画像認識技術は、Google Lensだけが特別なわけではありません。例えば現在のスマートフォン(スマホ)で当たり前となりつつある顔認証技術などは、まさにカメラに映された人の顔の特徴を判断し、それがスマホ所有者(権限を持つ人)本人であるのか、それとも他人であるのかを判断しているのです。
ただし、顔認証技術が人の「顔」に限定されているのに対し、Google Lensは世界中のすべての物体や事象を判断します。そこに巨大なハードルがあったことは疑う余地もありません。
Google Lensの開発者の1人でもある、Googleグループ プロダクトマネージャーのルー・ワン氏は「最も難しかったのは言語理解」だったと語ります。

画像認識技術について丁寧に解説するワン氏
例えば英語には約18万の単語があり、人々が一般的な会話で用いる言葉は3,000語程度だと言います。しかしこれが身の回りのものを示す名称や言葉となると、世界中で何十億という単位になるのです。
ある1つのオブジェクトの画像を取っても、それが上から見ているものなのか、横から見ているのか、清潔なのか、汚いのか、何色なのか……それら全てを判断しなければ、正しい画像認識は行なえません。
オブジェクトを限定しない認識には、コンピューターに判断のための膨大な知識と経験を積ませる必要があるのです。

Googleが長年の課題としたのは、やはりチワワとレーズンマフィンだった
■画像認識に必要な4つの要素
具体的には、機械学習という手法を用います。画像認識における機械学習では、以下の4つ手順が用いられます。
■クラシフィケーション(分類)
■ディテクション(検出)
■エンベディング(分散表現)
■モデルトレーニング(モデルの学習)
クラシフィケーションでは、ある画像の中の「要素」に注目します。画像に存在する物体や事象をざっくりと捉え、「ケーキ」、「風船」、「王冠」といった「ラベル」を付けます。そのラベルから可能性の高さを分析し、「これは93%の確率でケーキである」といった判断を行います。
ディテクションでは、ラベルが付けられた要素が画像のどこにあるのかを考えます。例えばケーキは左、王冠は右上、風船は左奥、といったように、各オブジェクトが何であるのかを選択的に考えます。

コンピューターは画像をそのままでは判断できない。細かく要素を分解して段階的に判断を深めていく
エンベディングでは、直感的な形でそのイメージ全体がどのような特徴を持っているのかを分析します。例えば「クルマ」、「左向き」、「クラシック」といったようにです。
機会学習では、画像の中の特徴を数値で表現し、複数の画像に与えられた数値を比較することで、「この画像はクラシックカーの画像である」などの判断を行います。この能力は、類似する品物や動物などを見つけるためにとても重要になります。

画像の特徴を数値化することで、別の画像と「似ているかどうか」の判断が行えるようになる
そして最後に必要なのがモデルトレーニングです。どれほど精密に分析や数値化を行えても、それを判断するための「材料」が少なければ意味を成しません。そのために膨大な時間と大量のデータ(物理的なサーバー数)が必要になったとワン氏は語ります。
しかしそこでもテクノロジーの進化があります。かつて膨大な時間をかけていた処理能力は、専用ユニットを開発することで劇的に削減され、それまで何ヶ月もかかっていた処理が今では数時間で完了するほどになりました。
モデルトレーニングの進化と発達は、そのまま画像認識精度の向上に繋がります。膨大な学習結果がさらに高い学習へと繋がり、指数対数的に処理性能を向上させます。その結果がGoogle Lensであり、手元のスマホで撮影された画像を一瞬で判断するほどになったのです。

かつて巨大なサーバーを必要とした処理も、今では1ボード化して圧倒的な高速処理を行えるように
■コンピューターが世界を「理解」する日
機械学習と画像認識技術は、私たちの生活にどんな変化を与えてくれるでしょうか。
例えば旅行先で何かの史跡を見つけた時、その史跡が何であるのかを知りたくなることがあります。Google Lensはそういった人々の興味や関心に寄り添うように、飽くまでも自然な形で情報を与えてくれます。
また発展的な使い方としては、靴やバッグを購入する際、それらの商品に似合う衣料品やアクセサリーを即座にレコメンドしてくれるビジネスが生まれるかも知れません。あらかじめユーザーの体型や年齢などを登録していれば、それらの情報も加味されたオススメも可能になるでしょう。
現在は画像に表示されたオブジェクトを認識するのみの機能だが、この機能こそが未来のAIアシスタントやオンラインビジネスの基礎となることは間違いない
現在のGoogle Lensはマネタイズなどを考えておらず、純粋にユーザーの利便性向上への技術的試金石として提供されるに留まっています。
スマホの顔認証技術が端末のロック解除やオンライン認証システムの鍵として利用される程度に留まっているように、そこにはプライバシーの問題や個人情報の取り扱い方の問題も大きく関わってくるからです。
しかし、間違いなく画像認識技術は広告ビジネスやオンラインショッピングの世界へと食い込んできます。ユーザーが何を見ているのか、そのユーザーの趣向は何なのか。それらをコンピューターが自動的に判断できるようになれば、企業にとっては効率の良いダイレクト広告も可能になり、ユーザーにとっては「欲しい物がすぐに見つかる」居心地の良い環境が揃うからです。

そもそもGoogleは広告ビジネスで育った企業である。自社のビジネスに有用であればこそ開発するのである
スマホが登場して十余年。世界のモバイルテクノロジーは一義的な進化ばかりしてきたように捉えられがちですが、その裏側の世界では劇的な変化が起こりつつあります。まるでスマホが世界を「理解」しているかのように的確な答えを返してくる背景には、このような地味で地道な技術の積み重ねが行われています。
スマホをチワワにかざして写真を撮れば、それをレーズンマフィンだと間違えるAIアシスタントは居なくなるのです。居酒屋で唐揚げの写真を撮っても、トイプードル用の餌ではなく唐揚げに合うお酒をレコメンドしてくれる世界がもうすぐ来るのです。
テクノロジーは人に優しく、扱いやすくあるべきものです。その未来を手元で試せる時代になったのです。
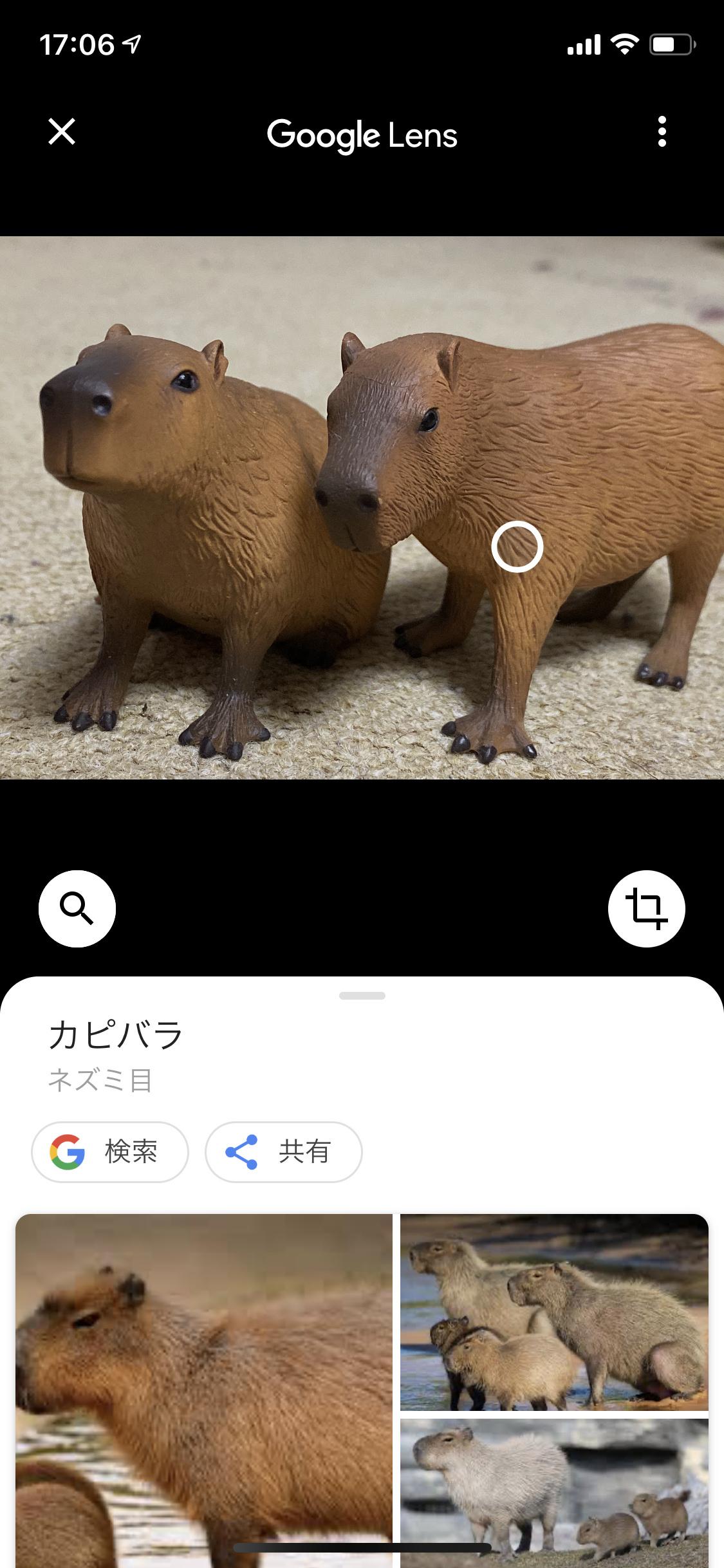
カピバラの生態だってすぐに教えてくれる。そう、Google Lensならね
■関連リンク
・エスマックス(S-MAX)
・エスマックス(S-MAX) smaxjp on Twitter
・S-MAX – Facebookページ
・連載「秋吉 健のArcaic Singularity」記事一覧 – S-MAX


コメント